Реализовано в версии 8.3.6.1977.
1С:Предприятие используется для автоматизации довольно широкого круга задач. Вопрос надёжности, безусловно, важен для каждой из этих задач. Однако есть две области применения 1С:Предприятия, в которых надёжность системы является не просто важной, а очень-очень важной. Это корпоративные внедрения и облачные сервисы.
В этих областях, как мы считаем, есть два направления для повышения надёжности:
Мы работаем в обоих направлениях. И в этой статье мы хотим рассказать про очередной шаг в направлении №2.
Этот шаг заключается в том, чтобы повысить защищённость сервера 1С:Предприятия от ошибок, которые могут возникнуть в его рабочих процессах. Это могут быть самые разные ошибки. Они могут быть следствием некорректной работы платформы. Или они могут возникнуть в результате выполнения некорректного прикладного кода, который исполняют рабочие процессы сервера.
Ошибки в рабочих процессах приводят к нескольким проблемам. Для устранения каждой узкой проблемы можно было бы сделать отдельный механизм. Но мы решили попробовать сделать сразу комплексное решение. Его рабочее название - система мониторинга. Мы понимаем, что название не совсем конкретное, но пока остановились на нём.
Суть системы мониторинга можно описать фразой из известной шутки: "В Одессе быстро поднятое не считается упавшим". А если говорить серьёзно, то задача системы мониторинга в том, чтобы своевременно обнаружить проблему и автоматически её исправить.
Систему мониторинга мы внедрили в процесс агента сервера. Каждые 10 секунд она производит опрос процессов кластера. В кластер может объединяться несколько рабочих серверов, каждым из которых управляет собственный агент сервера. Поэтому опрос процессов кластера производит только агент, управляющий центральным сервером:
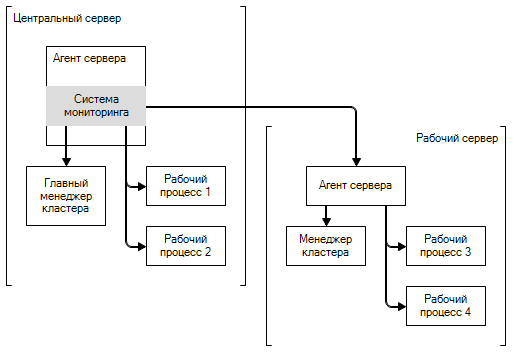
Опрашиваются все процессы, функционирующие в кластере: менеджеры кластера, рабочие процессы. Процессы, исполняемые на рабочих серверах, опрашиваются через агентов этих серверов. Таким образом дополнительно проверяется ещё и работоспособность самих агентов.
Каждый процесс система мониторинга проверяет по следующим критериям:
Результаты проверки записываются в технологический журнал.
Для настройки критерия Анализ количества ошибок на количество запросов мы ввели новую опцию Допустимое отклонение количества ошибок сервера. Её нужно задавать в процентном отношении от среднего значения по остальным процессам. Например, вы установили её в значение 50. При этом среднее количество ошибок на запрос в минуту за последние 5 минут было 100. Тогда проблемными будут признаны такие процессы, которые вызвали более 150 ошибок на запрос в минуту.
Процесс может быть признан проблемным и по другим критериям (кроме критерия Стандартный запрос). Проблемные процессы система мониторинга может завершать самостоятельно, создавая перед этим дамп памяти процесса. Эта возможность включается опцией Принудительно завершать проблемные процессы.
Для того чтобы вы могли интерактивно и программно управлять опциями системы мониторинга, мы внесли необходимые доработки в утилиту администрирования клиент-серверного варианта, добавили новые методы объекту V83.COMConnector, добавили новые параметры в кроссплатформенный интерфейс администрирования кластера и новые события в технологический журнал.
С началом использования системы мониторинга для нас будет важно понять, насколько правильно мы выбрали стратегию определения уровня «здоровья» рабочего процесса. Нет ли ложных срабатываний, качественно ли определяются реальные проблемы. В этом смысле самым сложным нам представляется параметр Допустимое отклонение количества ошибок сервера. Потому что это косвенный способ оценки. Будем вместе с вами смотреть на практике, хорошо ли это работает.
Система мониторинга не единственное решение, направленное на повышение надёжности. В ближайшее время мы расскажем и о другом усовершенствовании, которое сделает работу кластера более прогнозируемой при разрывах сетевых соединений.
