Реализовано в версии 8.3.7.1759.
Повышение надёжности 1С:Предприятия это одна из задач, которым мы уделяем постоянное внимание. Значительную роль здесь играет защищённость кластера от сбоев, которые могут произойти как аппаратных, так и в программных компонентах кластера. Для решения этих проблем в кластере существуют несколько направлений резервирования и механизм автоматического распределения нагрузки. При обнаружении сбоя этот механизм самостоятельно переведёт работу на резервные компоненты.
Однако прежняя архитектура кластера обладала таким недостатком, что возникновение сбоя не во всех ситуациях диагностировалось достаточно быстро. Например, при неисправности сети, при разрыве соединения между процессами кластера, могло пройти довольно длительное время до того, как механизмы отказоустойчивости и распределения нагрузки обнаруживали проблему. В результате функциональная нагрузка с недоступного узла кластера «перебрасывалась» неоперативно, со значительной задержкой.
Для того чтобы сократить время реакции кластера на разрыв соединения мы реализовали механизм отслеживания целостности сетевых соединений. Этот механизм отслеживает внутренние соединения между процессами кластера, и внешние соединения между кластером и расширениями веб-серверов.
Использование этого механизма позволяет, во-первых, оперативно обнаруживать разрывы связи между процессами, а во-вторых, снижает общие накладные расходы на отслеживание целостности соединений.
Проверка соединений осуществляется сразу для группы соединений, называемой направлением. Существуют правила, по которым платформа автоматически группирует несколько соединений в одно направление. Для каждого направления происходит периодическая отправка небольшого проверочного пакета данных, и ожидание ответа на него. Проверка осуществляется как на стороне источника этих соединений, так и на стороне приёмника.
Для отправки и приёма проверочных пакетов используются последовательно два протокола: UDP и TCP.
По этой причине при установке кластера и при публикации информационных баз на веб-сервере мы рекомендуем теперь обеспечить взаимную доступность между компонентами не только по TCP, но и по UDP с теми же номерами портов. Под компонентами в данном случае понимаются рабочие серверы кластера и компьютеры веб-серверов.
Алгоритм проверки выглядит следующим образом.
Пакеты отправляются по протоколу UDP. До наступления таймаута ожидается ответ. Если ответ получен, направление считается доступным, и проверка по протоколу UDP продолжается. Если в какой-то момент ответные пакеты UDP перестают приходить, направление считается недоступным.
Отдельно обрабатывается ситуация, когда за все время жизни направления не получено ни одного ответного пакета по протоколу UDP. В этом случае направление продолжает считаться доступным, но для дальнейшей его проверки будет использоваться протокол TCP. Устанавливается TCP соединение, и проверка идет через это новое соединение по тому же принципу. Если до наступления таймаута не пришло ни одного пакета от противоположной стороны по протоколу TCP, направление считается недоступным.
После того, как направление признано недоступным, все соединения этого направления помечаются как непригодные для использования, и будут разорваны при следующем обращении к ним. Кроме этого механизмы кластера оповещаются о разрыве соединений для оперативной реакции на это событие. В том числе для удаления блокировок, соответствующих недоступному процессу.
Механизм имеет два настраиваемых параметра:
Стандартные значения выбраны так, чтобы с большим запасом исключить ложные срабатывания при штатной загрузке сети и другого оборудования. В то же время эти значения обеспечивают комфортное время реакции на аварии на сетевом оборудовании, или на узлах кластера.
Мы предоставляем администраторам кластеров возможность отслеживать качество соединений между серверами и самостоятельно настраивать механизм. Для этого можно использовать технологический журнал. Раз в 10 секунд в него пишется статистика проверки. В частности, выводится информация о среднем времени ответа, и о максимальном времени ответа. На основании этой информации администратор может выставить минимальные таймауты, которые, не будут приводить к ложным срабатываниям системы проверки.
Примерный сценарий настройки может выглядеть следующим образом:
Для соединений внутри кластера значения периода проверки и таймаута вы можете задать с помощью параметров командной строки pingPeriod, и pingTimeout. Эти параметры можно использовать при запуске агента сервера как службы, «демона», или как приложения.
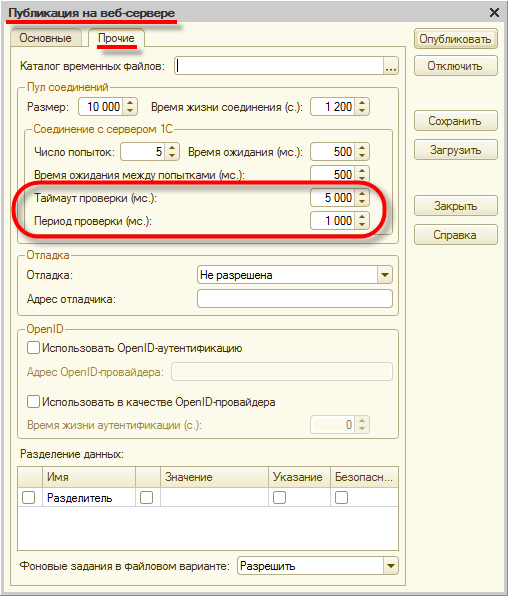
Для соединений кластера и веб-сервера период проверки и таймаут задаются в файле default.vrd, а интерактивно вы можете установить их в диалоге публикации информационной базы: